Sitting in a talk a year ago, at ITiCSE 2013, I heard the speaker make a familiar statement: “We all know that [Java] students mix up assignment and equality.” My colleagues and I have heard many such claims about what the most common Java student mistakes are (messing up the semi-colons, getting string comparison wrong, etc). With the launch of our Blackbox project, we had the opportunity to investigate these claims at a large scale. And not just investigate what mistakes students made, but also what mistakes the educators thought the students were making. I’d just been reading the Sadler paper which suggested educators’ knowledge of student mistakes was important, and it seemed interesting to investigate this issue in the context of learning to program in Java.
The results are published at this week’s ICER 2014 conference, in a paper with my colleague Amjad Altadmri. The paper is freely available; this blog post attempts to informally summarise the results. We got 76 complete responses from educators, and we had available data from 100,000 users via Blackbox. We tweaked a pre-existing classification of beginners’ Java mistakes into a set of 18. The plan was fairly straightforward: we asked the educators to assign frequency ratings to the 18 mistake categories (which we then transformed into a set of ranks). Then we looked at how often the students actually made the mistakes in those 18 categories. For our analysis, we compared educators to educators (do they agree with each other?) and educators to students (do their beliefs generalise to all students?).
Student Mistakes
Let’s start with the student data. The top five mistake categories actually committed by students were, in descending order:
- Mismatched brackets/parentheses.
- Calling a method with the wrong types.
- Missing return statement.
- Discarding the return type of a method. (Note: this is contentious because it is not always an error.)
- Confusing = with == (assignment with equality).
Everything is obvious in hindsight; so how did the educators fare with their predictions of frequency?
Educator Beliefs
Now on to the educator data. Our first surprise was that the educators did not agree with each other very strongly (equivalent Spearman’s correlation: 0.400). There were a few mistakes where the educators agreed “no-one makes that mistake”, but these “gimmes” actually boosted the educators’ agreement and accuracy. At the top end, there was little consensus on which were the most accurate couple of mistake categories.
Given this lack of agreement between educators, it is not a big surprise that the educators did not agree strongly with the student data (if all the educators predict fairly different rankings then, automatically, only a small number can be close to the student data, whatever it turns out to be). The average Spearman’s correlation between each educator and the student data was 0.514. This graph is an attempt to show what that looks like:
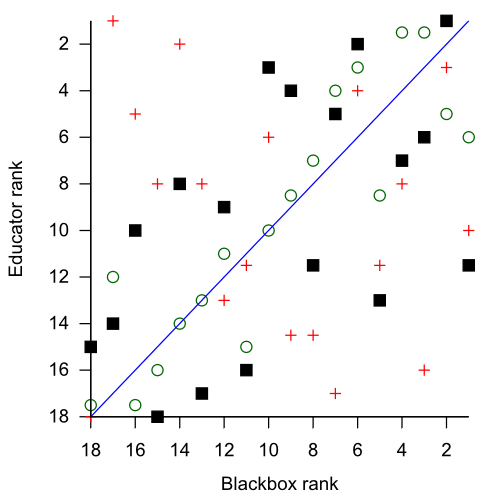
The diagonal line represents perfect agreement between frequency rank in Blackbox (X axis) and by the educator (Y axis). You can see that the best educator, shown as empty circles, comes pretty close to this ideal. But the educator with the median agreement, shown as black squares, was not really very close — for example, they assigned the 12th rank (of 18) to the mistake that was actually the most frequent. The red pluses are the worst educator, who had a negative correlation to the actual results.
So, educators in general did not predict the ranks very well. But it could be that the less experienced educators in our sample (e.g. around half had less than 5 years experience teaching introductory Java) are dragging down the scores of more experienced teachers. We checked for an effect of (a) experience in teaching, (b) teaching intro programming, or (c) teaching intro programming in Java specifically. And we found… nothing. Experience (measured as a, b or c) had no significant effect on educators’ ability to predict the Blackbox mistake frequencies. In graphical form, here is an example match between experience teaching introductory programming in Java (X axis) and prediction of Blackbox data (Y axis):
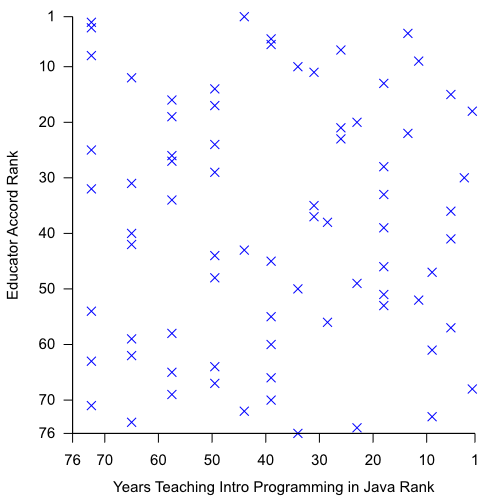
A great example of a lack of correlation! If you want more details on the results or exact methodology we used, please read the paper.
Conclusions
So, what can we take from this study? Well, we could take the results and head off on a jolly crusade: “Teachers know very little about the mistakes their students make, and experience is worthless!” But we have explicitly not pushed this interpretation. There are several more plausible reasons for our results. Firstly, I think ranking student mistakes is a difficult task, and one that does not necessarily align well with teacher efficacy. Sadler’s paper looked at whether teachers could predict the likely wrong answer to a specific question; we ask here about most frequent mistakes across a whole term/semester of learning, which is a different challenge. It seems likely that this task is too alien to educators, and thus they all struggle with it, regardless of experience.
Another factor that came up in comments after the paper presentation (I think by Angelo Kyrilov, but maybe someone else too?) was that it may matter which environment teachers are using to program — IDEs like Eclipse may minimise the incidence of bracket errors when smart bracketing is used, in contrast to BlueJ (which all the students in our data set used). I don’t think this would explain the whole pattern, but in hindsight I wish we had captured this information when we surveyed the educators.
We can draw two fairly definite conclusions from our study. Firstly: beware any educator who tells you what the most common mistakes students make are. You’ll get a different answer from their colleague and they are unlikely to be accurate on a wider scale. (They may, of course, be spot on about their own class — but unless you teach their class, that is not really relevant to you.) Secondly: our results for the frequency of different student mistakes, available in the paper, must be surprising. After all, none of our participants predicted them!

One thought on “Educator Beliefs vs Student Data”